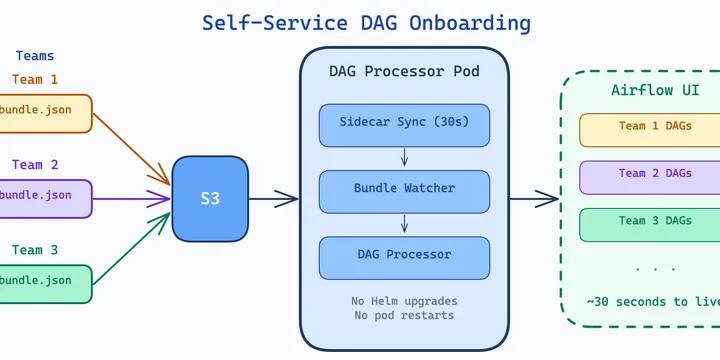
Airflow DAG Bundles: Managing DAGs Across Teams Without Helm Upgrades
How we use S3 DAG bundles, a sidecar sync pattern, and the bundle watcher to onboard new pipelines with zero downtime.
airflow kubernetes data-engineering dag-bundles
$ echo "building the future of ad tech"
Deep dives into architecture, data engineering, and the tools we build.
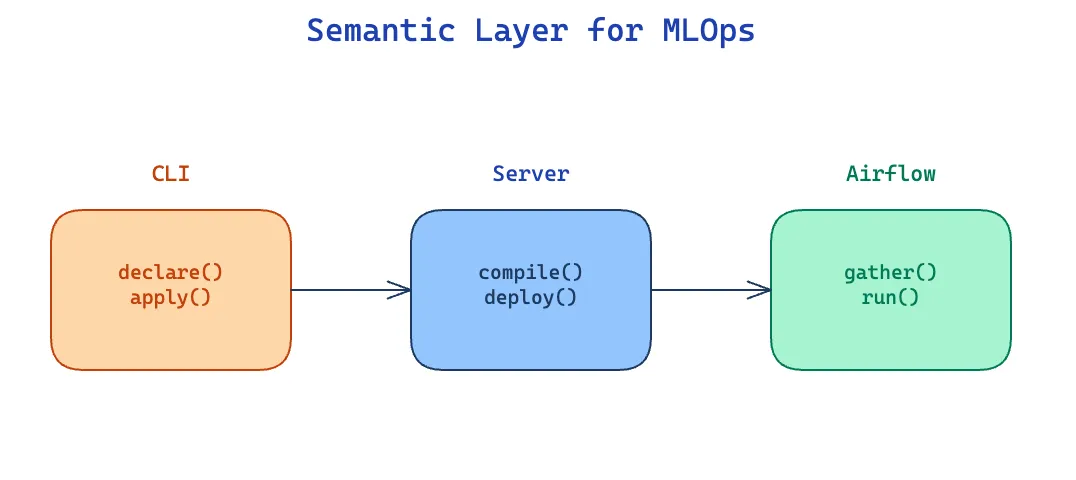
Six ideas about feature stores, AST-generated ETLs, content-addressed artifacts, and control planes — distilled from building a semantic layer for ML.
How we use S3 DAG bundles, a sidecar sync pattern, and the bundle watcher to onboard new pipelines with zero downtime.
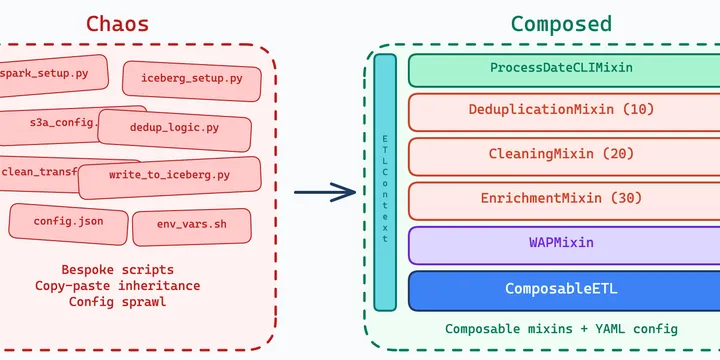
How we replaced bespoke PySpark scripts with a config-driven, hook-based framework inspired by Rust's composition model.
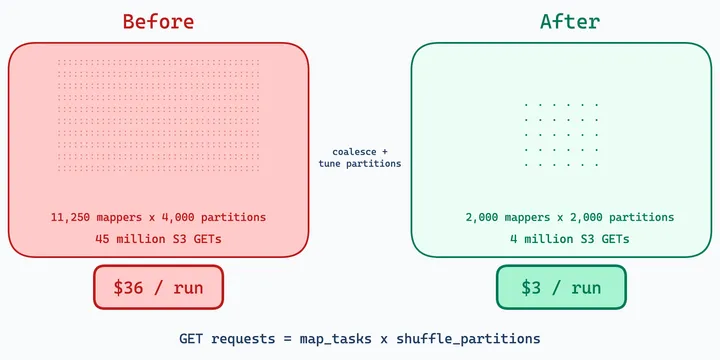
How we fixed the GET request explosion, prefix throttling, and threading edge cases that emerge when S3 shuffle meets production scale.
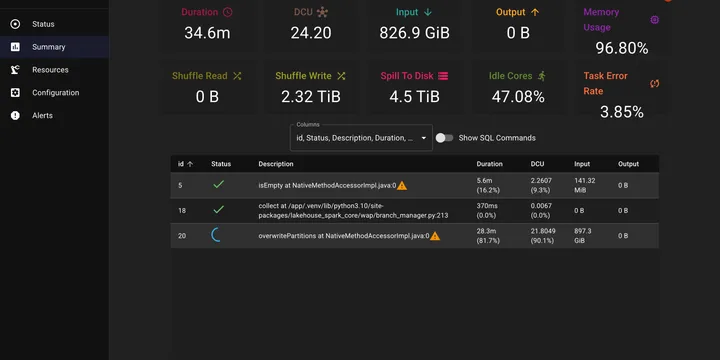
How an open-source Spark UI replacement helped us find data skew, partition bloat, and shuffle spill.
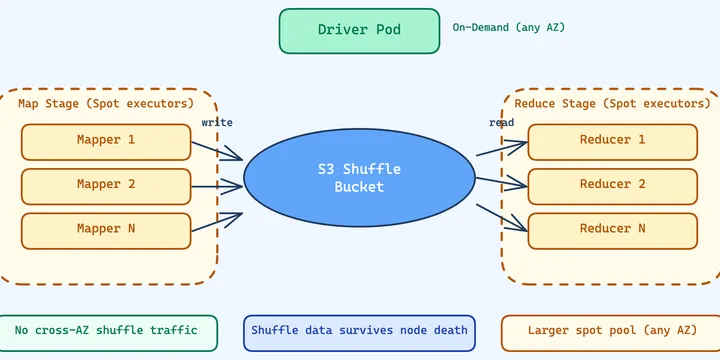
How S3 shuffle lets us run Spark executors 100% on spot instances with Karpenter, cutting compute costs 70-85%.
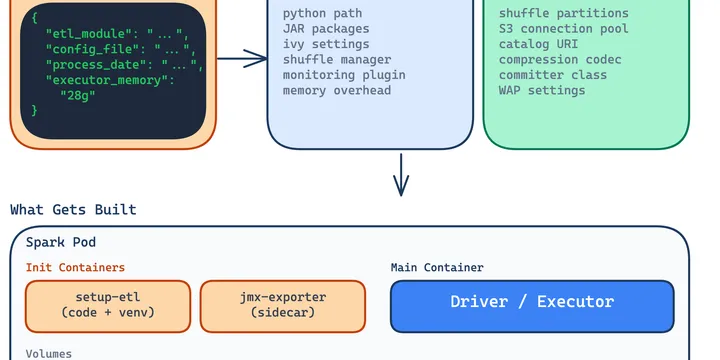
How we run production Spark jobs on Kubernetes with one SparkApp YAML, pre-baked images, and sub-10-second warm starts.