Taming S3 Shuffle at Scale
How we fixed the GET request explosion, prefix throttling, and threading edge cases that emerge when S3 shuffle meets production scale.
In Part 1, we described how S3 shuffle decouples shuffle storage from ephemeral compute, letting us run Spark executors 100% on spot instances. The architecture works — shuffle data survives node death, Karpenter provisions replacements in ~30 seconds, and we save 70-85% on compute.
Then we scaled up. At thousands of map tasks and high executor concurrency, we hit three categories of problems: an S3 request explosion from the per-mapper file design, S3 prefix rate limiting, and threading edge cases that caused executor hangs. The first two we solved with configuration. The third required production hardening patches to the plugin.
The GET Request Explosion
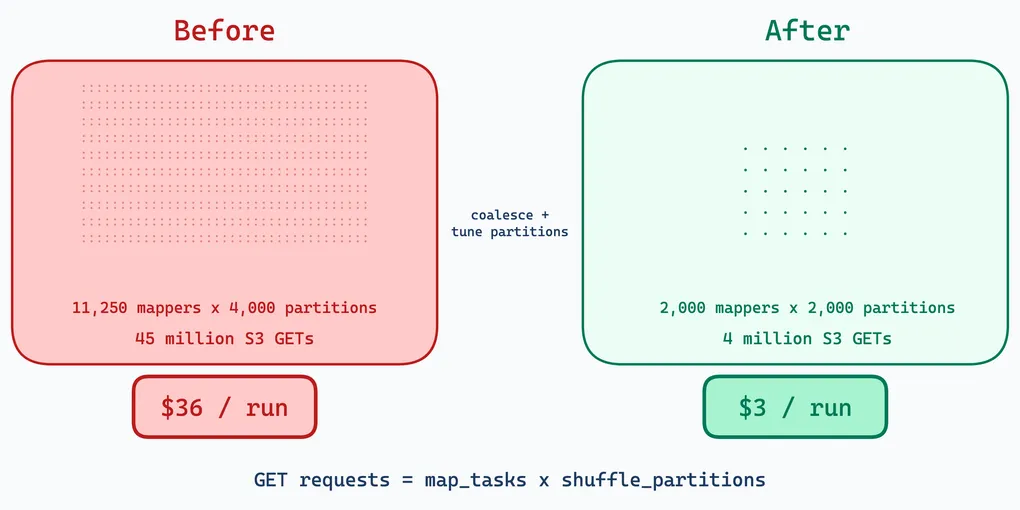
The upstream S3 shuffle plugin writes one .data file per map task, with a companion .index file that stores byte offsets for each reduce partition. On the read side, each reducer opens a separate S3 stream for every mapper that produced data for its partition. The S3 GET count scales as O(mappers x reducers).
We found out the hard way. Our input data consisted of thousands of Parquet files — Spark created one map task per file. Even a one-month backfill produced ~3,750 map tasks, and with spark.sql.shuffle.partitions set to 4,000, that is 15 million S3 GETs per shuffle stage. A three-month window pushed it to 45 million. At S3’s standard GET pricing ($0.0004 per 1,000), a single three-month backfill cost us $36 in S3 GETs alone — just API calls, before data transfer.
The quadratic scaling makes this worse fast:
| Time Window | Map Tasks | Shuffle Partitions | S3 GETs (per stage) | Cost (2 stages) |
|---|---|---|---|---|
| 1 month | ~3,750 | 4,000 | 15M | ~$12 |
| 3 months | ~11,250 | 4,000 | 45M | ~$36 |
| 6 months | ~22,500 | 4,000 | 90M | ~$72 |
The root cause was not the plugin’s design alone — we were creating far more map tasks than necessary. A wide time window meant reading thousands of input files, each becoming its own map task, where coalescing them into fewer partitions would suffice.
The Fix: Coalesce Input + Tune Partitions
This mitigation required zero plugin changes. The fix is to reduce both sides of the multiplication. Coalesce input files into fewer, larger partitions to reduce map tasks. Tune spark.sql.shuffle.partitions to match your actual parallelism needs.
GET_requests ≈ map_tasks × shuffle_partitions × num_shuffle_stagesFor our backfills, coalescing alone dropped map tasks from thousands to ~2,000, and tuning shuffle partitions brought the GET count into a manageable range. A three-month backfill went from 45 million GETs ($36) to around 4 million GETs per stage — an order of magnitude reduction in S3 API costs.
S3 Prefix Throttling
AWS S3 enforces rate limits per prefix: 5,500 GET/HEAD requests per second and 3,500 PUT/COPY/POST/DELETE per second. The plugin distributes shuffle files across multiple prefix folders using mapId % folderPrefixes to spread the load.
With the default 10 prefixes, you get a budget of 55,000 GET/s across all prefixes. That sounds generous — until you have tens of millions of GETs in a shuffle stage. At 55K GET/s, draining 15M GETs (a one-month backfill) takes ~4.5 minutes of pure rate-limited waiting per stage. A six-month window at 90M GETs takes ~27 minutes per stage. That is nearly an hour of your job spent just waiting on S3 rate limits — before any actual data processing. And in practice, contention from concurrent reduce tasks hitting the same prefixes means you start seeing S3 503 SlowDown errors well before the theoretical limit.
The Fix: Scale Prefixes Per Workload
The fix is simple: set spark.shuffle.s3.folderPrefixes to a generous value. We use 500 across all our jobs. The tradeoff is increased listStatus overhead when cleaning up shuffle files (one list call per prefix). Alternatively, set spark.shuffle.s3.cleanup to false and let S3 bucket lifecycle policies handle cleanup — ours expire shuffle data after a day.
Production S3A and Shuffle Tuning
Beyond the GET and prefix fixes, we tuned the Hadoop S3A client and shuffle plugin settings:
# S3A client tuning — maximize throughputspark.hadoop.fs.s3a.fast.upload: "true"spark.hadoop.fs.s3a.fast.upload.buffer: "bytebuffer"spark.hadoop.fs.s3a.max.total.tasks: "500"spark.hadoop.fs.s3a.threads.max: "500"spark.hadoop.fs.s3a.connection.maximum: "500"spark.hadoop.fs.s3a.input.fadvise: "random"spark.hadoop.fs.s3a.committer.name: "directory"spark.hadoop.fs.s3a.connection.timeout: "60000"spark.hadoop.fs.s3a.attempts.maximum: "3"
# Shuffle plugin tuningspark.shuffle.checksum.enabled: "false"spark.shuffle.s3.bufferSize: "268435456" # 256 MBspark.shuffle.s3.maxBufferSizeTask: "2147483648" # 2 GBspark.shuffle.s3.maxConcurrencyTask: "50"spark.reducer.maxSizeInFlight: "256M"A few notes:
- 500 connections/threads: Each executor needs enough S3 parallelism to saturate its network link. 500 is high but these are I/O-bound threads waiting on network responses, not CPU-bound.
bytebufferuploads: Uses off-heap direct byte buffers for S3 uploads, avoiding GC pressure on the JVM heap.randomfadvise: Tells the S3A client to optimize for random access patterns (shuffle reads), not sequential scans.- Checksums disabled: S3 provides its own data integrity guarantees. The plugin’s per-partition checksums create additional S3 objects and add CPU overhead during reads with no practical benefit.
- LZ4 compression: All our ETLs use LZ4 for shuffle data. It is designed for speed over compression ratio — the bottleneck is S3 I/O latency, not bandwidth.
All shuffle data flows to a dedicated ephemeral S3 bucket with per-ETL prefixes. This isolates shuffle traffic from production table I/O and allows aggressive lifecycle policies for cleanup.
Production Hardening: Threading Edge Cases
Config tuning solved the GET explosion and prefix throttling. But at high concurrency (30+ cores per executor, hundreds of concurrent prefetch threads), we started seeing executors hang and get killed by the driver for missing heartbeats. The Spark UI showed tasks stuck indefinitely — not slow, just frozen. This pointed to threading edge cases in the plugin that do not surface at moderate scale.
We traced it to two issues and contributed fixes in our fork.
ConcurrentObjectMap: Cache Corruption from Non-Atomic Operations
The plugin uses ConcurrentObjectMap to cache index files and checksums — data that gets read repeatedly by multiple reduce tasks. The upstream implementation uses Scala’s TrieMap with a pattern that is not atomic under high concurrency:
// Upstream — race condition under high concurrencyval l = valueLocks.get(key).getOrElse({ valueLocks.getOrElseUpdate(key, { new Object() })})The problem: valueLocks.get(key) and valueLocks.getOrElseUpdate(key, ...) are two separate operations on a TrieMap. Between them, another thread can insert the same key. This leads to two threads holding different lock objects for the same key — which means the lock does not actually serialize access.
Our fix replaces TrieMap with ConcurrentHashMap and uses computeIfAbsent for atomic lock creation:
// Fixed — atomic per-key lockingval lock = keyLocks.computeIfAbsent(key, _ => new Object())lock.synchronized { Option(map.get(key)).getOrElse { val value = op(key) map.put(key, value) value }}ConcurrentHashMap.computeIfAbsent is atomic — it guarantees that only one lock object is created per key, so two threads requesting the same key always serialize correctly.
S3BufferedPrefetchIterator: Memory Lock Deadlock
This was the bigger issue. The S3BufferedPrefetchIterator prefetches shuffle blocks in background threads to hide S3 latency. The upstream implementation uses synchronized(this) for everything — memory management, the completed-blocks queue, and thread lifecycle all share the same monitor lock. At moderate concurrency this works fine, but with 30+ cores and dozens of prefetch threads competing for the same monitor, the following scenario becomes likely:
- A prefetch thread holds the lock, waiting for memory to become available (
wait()insidesynchronized) - The consumer thread (Spark task) calls
next()to consume a prefetched block, which would free memory - But
next()also needssynchronized(this)— blocked because the prefetch thread holds it - Deadlock: prefetch thread waits for memory, consumer waits for the lock, neither can proceed
Our fix separates the concerns:
- Memory management gets its own
memoryLockobject — prefetch threads wait on this, not the main monitor - Completed-blocks queue replaced with
LinkedBlockingDeque— thread-safe without holding any lock - 5-second timeout on memory allocation — if memory is not available, the block streams unbuffered instead of deadlocking
- 30-second timeout on
next()— throwsTimeoutExceptioninstead of hanging forever
// Separate memory lock — no more deadlock with consumermemoryLock.synchronized { val deadline = System.currentTimeMillis() + MEMORY_WAIT_TIMEOUT_MS while (memoryUsage + bsize > maxBufferSize && !timedOut) { val remaining = deadline - System.currentTimeMillis() if (remaining <= 0) timedOut = true else memoryLock.wait(remaining) }}
// Consumer polls from thread-safe deque — no synchronized neededresult = completed.pollFirst(100, TimeUnit.MILLISECONDS)This deadlock was likely the root cause of the executor hangs and heartbeat timeouts we were seeing. Once the lock was separated and timeouts were added, executors stopped hanging.
Missing Reliable Storage Declaration
The upstream plugin does not declare supportsReliableStorage(). Without it, Spark does not know that shuffle data is durable in S3, which means it cannot safely decommission executors on spot interruption. We added a four-line override:
override def supportsReliableStorage(): Boolean = { true}This tells Spark’s BlockManagerDecommissioner to skip shuffle block replication when an executor is being drained — the data is already safe in S3.
Compatibility: BypassMergeSortShuffleWriter
One more fix that is not about scale but about deployment. When the plugin is loaded via spark.jars.packages (fetched from a Maven repository at runtime), the BypassMergeSortShuffleWriter class is not directly accessible because it has package-private visibility in org.apache.spark.shuffle.sort. The upstream code calls new BypassMergeSortShuffleWriter(...) directly, which fails with an IllegalAccessError.
Our fix uses reflection to instantiate it:
val clazz = Class.forName( "org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter")val constructor = clazz.getDeclaredConstructor(...)constructor.setAccessible(true)constructor.newInstance(...)This is a deployment issue, not a scale issue — but it was a blocker for running the plugin in production on Kubernetes where JARs are resolved via Ivy at spark-submit time.
Summary
| Problem | Fix | Where |
|---|---|---|
| GET explosion (O(M x R)) | Coalesce input + tune partitions | Config (95% reduction) |
| S3 prefix throttling (503 errors) | Scale folderPrefixes 20-500 | Config |
| S3A throughput | 500 connections, random fadvise, LZ4 | Config |
| ConcurrentObjectMap race condition | ConcurrentHashMap + per-key locking | Fork |
| Prefetch iterator deadlock | Separate memory lock + timeouts | Fork |
| Missing supportsReliableStorage() | Declare true for safe decommissioning | Fork |
| BypassMergeSortShuffleWriter access | Reflection for package-private class | Fork |
The config-level fixes are worth doing regardless — they apply to anyone using the S3 shuffle plugin. Input coalescing and partition tuning alone can cut S3 API costs by an order of magnitude. Prefix scaling eliminates throttling. S3A tuning maximizes throughput.
The production hardening patches address threading edge cases that surface at high concurrency — 30+ cores per executor with hundreds of concurrent prefetch threads. The upstream plugin works well at moderate scale; these fixes extend it to high-concurrency environments. Our fork is available with all patches applied, targeting Spark 4.0 and Scala 2.13.