What We Learned Building Our ML Platform
Six ideas about feature stores, AST-generated ETLs, content-addressed artifacts, and control planes — distilled from building a semantic layer for ML.
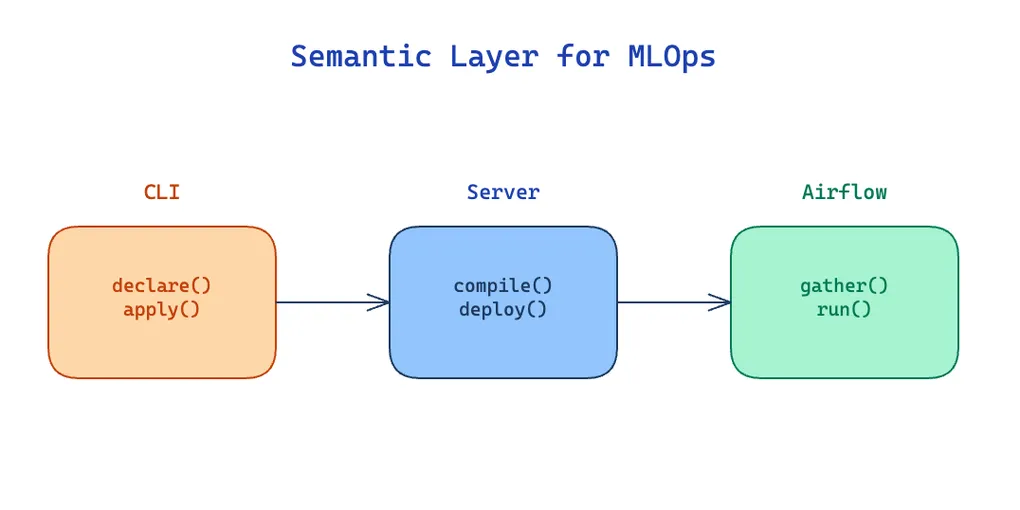
We have been shipping ML on a lakehouse for a while. What was missing was a layer above our cohorts, features, labels, and models that knew how they related — training sets, inference sets, and model versions were wired by hand on every new project. So we built one. We call it Zest. This post is not about Zest. It is about six choices we made along the way.
The short version:
- Everything is a transformation.
- ETLs are generated from declarations, not written by hand.
- Execution modes are compile-time, not runtime.
- The artifact layer should be dumb. The control plane should be smart.
- Declare dependencies, not pipelines. The graph does change propagation, scope, and ordering for free.
- Don’t build an orchestrator. Build a payload factory.
1. Everything is a transformation
The default mental model for ML infrastructure is a pile of specialized systems. Features live in a feature store, one row per entity-time-feature. Labels live in a training table. Models live in a model registry, keyed by version. Datasets get rebuilt every time by whatever training script runs last. Each concept has its own substrate, its own API, and its own notion of versioning. The relationships between them — which features this model uses, which cohort scoped those features, which label the training set joined against — live in the pipelines that stitch them together.
So we consolidated. Every ML resource — a feature family, a cohort, a label, a training dataset, a model — is a declaration in one graph. The resources that compute something compile to the same primitive: a content-hashed, dependency-tracked transformation. Those compiled transformations are what Zest versions and ships; the outputs themselves (Iceberg tables, model artifacts) live where they always did. Individual features are named columns within a family’s output, addressable by name but not themselves compiled. Model versions, entities, sources, and schemas stay as registry rows — pure metadata in the same graph. What’s unified is the shape of the computation, not the fact that metadata exists.
The consequence of this reframing runs through everything else in this post. If you treat ML work as stored outputs, you build a storage product. If you treat it as compiled transformations, you build a compiler. The two products diverge almost immediately: the storage product optimizes for read latency, online/offline consistency, and a global key space. The compiler product optimizes for version discipline, dependency graphs, and deterministic builds.
The payoff of going the compiler route is uniformity. Cohorts, labels, feature families, training datasets, inference datasets, evaluation jobs — everything in the ML lifecycle ends up as one of two things on the execution side: a SparkJob or a RayJob. The resource types above that layer stay semantic (business-meaningful names like “high-value customers” or “churn probability”). The execution surface stays narrow.
2. ETLs are generated from declarations, not written by hand
The first consequence of “features are transformations” is that the platform has to produce those transformations. We chose to produce them the same way a programming language produces executables: by compiling a declaration at a well-defined moment, emitting deterministic source, and storing the output as a content-addressed artifact.
The moment is apply. In our SDK, you declare a resource — a cohort, a feature family, a model — and then run client.apply(). On the server, apply walks the declaration, builds a Python ETL script node by node using the ast module, unparses it to source, hashes the source, stores it in an artifact repository, and writes the artifact id back onto the transformation row. It is the same shape as terraform apply, but the thing being provisioned is an ETL, not a cloud resource.
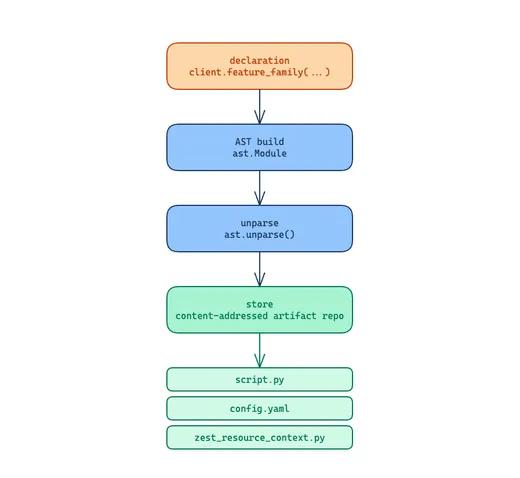
We do not use string templates. String-based code generation was the shortest path at the start of the project, and we backed away from it for two reasons. The first is safety: a malformed template produces broken Python that only fails at runtime. AST construction fails at compile time, which means “the platform can build your ETL” becomes part of the apply contract. The second is composability: hooks get attached to named extension points, mixins compose through multiple inheritance, schema classes get inlined. All of that is awkward in templates and straightforward in AST nodes.
A compiled script has an opinionated shape. The generated class inherits from ComposableETL, the base our sibling framework lakehouse-spark-core provides, then from one synthesized mixin per declared hook, then from a CLI mixin that decides how the script interprets command-line arguments at run time. Here is the shape:
# Compiled by Zest for transformation: spending_features_dailyfrom lakehouse_spark_core import ComposableETL, ProcessDateCLIMixin
# ... one synthesized hook mixin class per declared hook (elided)
class SpendingFeaturesDailyETL( ProcessDateCLIMixin, FilterByCohortMixin, # from the cohort dependency WindowedSpendingMixin, # from the feature declaration ComposableETL,): """Generated ETL class for transformation: spending_features_daily"""
def main(): SpendingFeaturesDailyETL.cli_main()
if __name__ == "__main__": main()Nothing interesting happens in main. All the logic lives in the mixins. The ETL framework’s hook registry walks the class MRO at instantiation, finds methods decorated with @register_hook(ProcessingHook.POST_EXTRACT, priority=20), and dispatches them at the right pipeline phase. The compiler produced the MRO. The runtime discovers it reflectively. The two systems never need to know each other’s internals.
Hook mixins are not the only thing the compiler injects. Every name in the declaration — the source tables, the target table, the upstream cohort’s path, the feature columns this transformation produces, the label’s output column, the entity’s primary key and partition fields, the hooks and schemas referenced by name (swapped for their content-hashed artifact IDs), the CLI mixin that decides argument parsing, the Spark execution context for this profile (coalesce, memory, partition counts) — gets resolved to concrete values at compile time and baked into the artifact’s config.yaml and an accompanying zest_resource_context.py. At run time, the compiled ETL does not call back to Zest; it never looks anything up by name. The declaration is name-oriented on the way in; the artifact is fully resolved on the way out.
None of this would work without the runtime underneath. lakehouse-spark-core already knows how to set up a Spark session, read and write Iceberg tables, tune S3A, sequence Write-Audit-Publish, handle empty data, and emit structured logs. The compiler does not generate any of that. It emits a ten-line shell that inherits those capabilities from ComposableETL and composes the specific hooks this transformation wants. That split — a thin composition shell over a thick runtime — is what makes AST emission at apply time tractable. The compiler is stitching together primitives the runtime already provides, not writing a Spark job from scratch.
Two deeper points follow.
First, apply is idempotent. The server hashes the declared config first and compares it to the hash on the latest row. If the hashes match, the upsert returns unchanged and compilation never runs. Apply becomes “hash the declaration; compile only if the hash is new.” That is the same check plan reports against.
Second, apply is cheap because compilation is the expensive step, and it only runs when content changes. Storing artifacts is a write-through with content-addressed dedup. Re-applying a workspace with 200 unchanged resources does nothing on disk. A developer can tighten a hook, re-apply, see exactly which downstream transformations’ hashes changed, and only pay for the ones that actually moved.
3. Execution modes are compile-time, not runtime
An ETL typically has variants: a daily incremental run, a full-table backfill, a historical reprocessing from a tagged snapshot. The common default is to encode the variants inside one script with a runtime switch — if execution_mode == "backfill": .... We used to do this too. It is the wrong layer to decide.
Our platform replaced the execution_mode flag with profiles. A profile is a named execution variant declared as part of the resource, and at apply time each profile compiles to its own transformation — its own script, its own config, its own content hash. A feature family with daily, backfill, and historic profiles produces three distinct compiled artifacts. The runtime script never branches on mode, because the branches are resolved at compile time.
client.feature_family( name="spending_features", profiles={ "daily": {"sources": [...prune_date_partitions=True], "lookback_days": 95, ...}, "backfill": {"cli_mixins": ["DateRangeCLIMixin"], "coalesce": (900, 300, 450), ...}, "historic": {"sources": [...tag="{process_date}"], "lookback_days": 185, ...}, },)Each profile gets to diverge arbitrarily. daily uses partition pruning and a single-date CLI mixin. backfill uses a date-range mixin and heavier coalesce settings. historic reads from a tagged Iceberg snapshot with a longer lookback. These are different operational shapes, not different runtime arguments. Trying to express them inside one branching script hides the divergence inside conditionals and forces Spark to choose plans at runtime.
The broader principle this surfaced: anything that can be decided at compile time should be decided at compile time. Runtime conditionals are expensive — in complexity, in debuggability, in operational blast radius. A resource with three profiles is three rows in the registry, three scripts, three config blobs — and the runtime has zero branches. That is a trade we take every time.
4. The artifact layer should be dumb. The control plane should be smart.
The ETL framework we built Zest on top of holds data. Zest itself holds relationships. The division is not accidental. Every system that carries metadata about compiled code, versions, or lineage should decide early where the relationships live, and we decided everything metadata lives in Postgres and everything byte-level lives in a content-addressed blob store with exactly this interface:
class ArtifactRepository(ABC): async def store(self, artifact: Artifact) -> str: ... async def retrieve(self, artifact_id: str) -> Artifact: ... async def exists(self, artifact_id: str) -> bool: ... async def delete(self, artifact_id: str) -> bool: ...No list. No search. No filter. No query. No indexes. If you want to find something, you ask Postgres, which answers with an artifact id, which the store resolves to bytes. The store is a hash map.
Artifact ids are content-addressed:
compiled_script-spending_features_daily-1.0.0-3f2a4b1cThe first three parts (type-name-version) are human-readable. The last part is the md5 of the content, truncated to 8 hex characters. Same content, same id, always. Writing the same bytes twice is a no-op. Rolling back a deploy is a pointer update on the transformation row, not a rebuild. Dedup across similar transformations is automatic.
Making the store this boring is what keeps the control plane coherent. Every constraint we care about — “latest version of a named resource”, “all resources owned by this workspace”, “all transformations deployed at 2026-04-22T03:00Z” — is a Postgres query on metadata we already have. The store never has to answer a relational question, which means the store is trivially swappable. Local filesystem in dev. S3 in prod. Something else tomorrow. Three methods.
5. Declare dependencies, not pipelines
The standard mental model for a pipeline platform is “author a DAG.” Users wire tasks together, specify execution dependencies, and the platform runs them in order. Zest has a graph too, but no one authors it as a pipeline. Users declare resources and name the resources they depend on. The platform assembles the graph from those declarations and uses it for three things that would otherwise be manual work.
Change propagation is automatic. When the server hashes a resource, it folds in the resolved artifact ids of its declared upstream dependencies. If a hook’s code changes, every transformation that references that hook gets a new hash on the next apply, and plan surfaces them as updated. Nobody wrote “if hook changes, invalidate dependents.” The dependency-aware hash handles it.
Scope is a traversal. When an operator says “deploy this model” or “build the orchestration payload for this cohort’s daily profile,” the platform walks the declared graph from the named root — we call it an anchor — and collects the reachable set. zest deploy model X uses the walk to find which artifacts to ship to object storage. POST /orchestration/query uses the same walk to build the ordered list of transformations for a downstream orchestrator. The walk is a lookup over declared edges, not an execution plan in itself.
Ordering is free. Apply processes resources in tier order, flushing between tiers so downstream declarations see upstream writes. A feature family that references a hook cannot be processed before the hook has a row in the registry. The ordering falls out of the declared graph; nobody writes it.
Authoring a DAG of tasks gets you execution ordering and nothing else. Declaring dependencies gets you change propagation, scope queries, and ordering together — because all three read from the same graph.
The operator benefit is that the graph is the platform’s single source of truth for relationships. An engineer changing a hook does not have to find the ten transformations that use it. An engineer deploying a model does not have to list its upstream feature families. The graph already knows.
6. Don’t build an orchestrator. Build a payload factory.
This is the smallest idea in scope and the largest in consequence. We did not arrive at it by foresight — we built an orchestrator first, ran it, and scrapped it. What follows is the shape we settled on after.
Zest does not schedule anything. It does not trigger jobs. It does not retry failed runs, it does not queue backfills, it does not alert on missing watermarks. It builds payloads. A payload is a strictly-typed JSON object describing one transformation that needs to run:
{ "resource_type": "feature_family", "resource_name": "spending_features", "profile_name": "daily", "entity_name": "customer", "transformation_name": "spending_features_daily", "transformation_id": "txn-a1b2c3...", "job_type": "spark", "version": 1, "workspace": "test", "execution_context": { "driver_cores": 2, "driver_memory": "3g", "executor_instances": 2, "executor_cores": 2, "executor_memory": "4g", "executor_node_labels": { "spark-role": "memory-intensive-executor-shuffle" } }, "tags": ["features", "spending", "daily"]}An Airflow DAG calls our orchestration query endpoint, receives an ordered list of payloads, and fans them out to Kubernetes SparkApplications. An agent doing the same job would receive the same payloads and submit them to whatever execution backend it likes. What runs them is not our problem. What should run is.
The scope discipline of this split matters. The orchestration space is crowded and well-served — Airflow, Prefect, Dagster, Argo, Temporal, everyone has one. The “figure out what to run” space, for a declarative ML control plane, was not. We built in the gap, and we stayed small by refusing to grow into the adjacent space. Our surface area is payloads in and artifacts out. Everything in between — the actual compute — belongs to someone else.
A related benefit: refusing to own scheduling kept us honest about where the sources of truth live. The “did this job succeed?” question gets answered by the orchestrator. The “did the data land?” question gets answered by the Iceberg table itself. Zest declares intent. It does not report outcomes. We never had to reconcile a third system claiming to know either.