Building a Composable ETL Framework for Spark
How we replaced bespoke PySpark scripts with a config-driven, hook-based framework inspired by Rust's composition model.
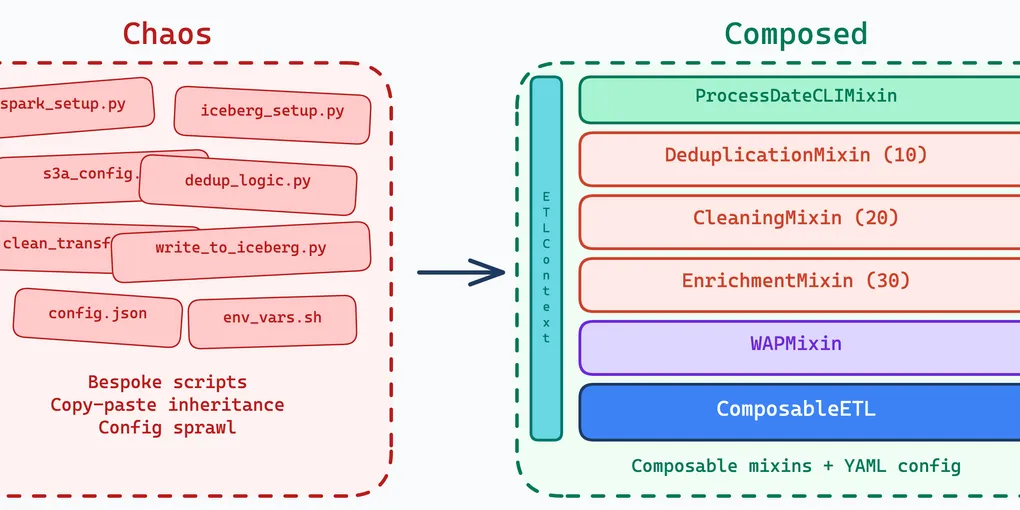
Most data teams hit the same problem eventually: every pipeline is written differently. The boilerplate — Spark session setup, Iceberg catalog registration, S3A client tuning, shuffle configuration — gets repeated in every project. New pipelines start as copies of old ones. Bugs in shared patterns have to be fixed everywhere individually.
We built a framework that standardizes the infrastructure without constraining the business logic.
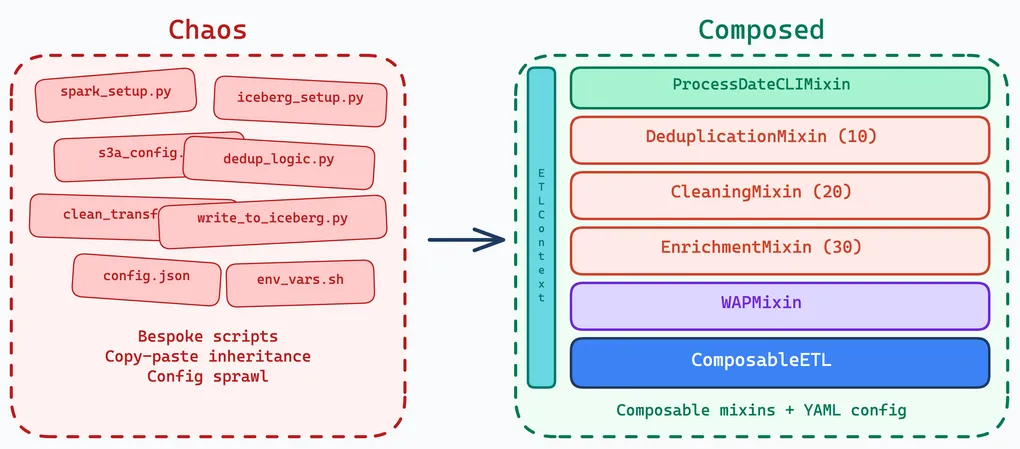
Composition Over Inheritance
The instinct with ETL frameworks is to build a deep class hierarchy: BaseETL → SparkETL → IcebergETL → DailyIcebergETL. Each layer adds behavior, each layer constrains the next. By the time a data engineer subclasses the leaf, they are fighting the framework more than using it.
We took inspiration from Rust’s trait system instead. In Rust, you compose behavior by implementing traits on a type — there is no inheritance hierarchy. The type declares what capabilities it has, and the compiler ensures everything fits together. Python does not have traits, but it has mixins and the strategy pattern, which achieve the same goal.
Our ComposableETL base class accepts pluggable strategies for each phase of the pipeline: extractors read data, transformers process it, compactors write it. Cross-cutting concerns — CLI argument parsing, Write-Audit-Publish, empty data handling — are mixins that compose independently.
Here is what a production ETL looks like:
from lakehouse_spark_core import ComposableETL, ProcessDateCLIMixinfrom lakehouse_spark_core.mixins import WAPMixinfrom helpers.deduplication_hook import DeduplicationMixinfrom helpers.cleaning_hook import CleaningMixinfrom helpers.enrichment_hook import EnrichmentMixin
class DataCleaningETL( ProcessDateCLIMixin, WAPMixin, DeduplicationMixin, CleaningMixin, EnrichmentMixin, ComposableETL,): """Transforms raw data into cleaned, standardized format."""That is the entire class. No method overrides, no abstract method implementations. All behavior is composed from mixins:
ProcessDateCLIMixin— adds--process-dateand--configCLI argumentsWAPMixin— enables Write-Audit-Publish with branch-based atomic writesDeduplicationMixin— removes duplicate records by a composite keyCleaningMixin— drops columns, trims whitespace, standardizes text, filters invalid dataEnrichmentMixin— adds derived columns and mappings
Each mixin is reusable. CleaningMixin can be mixed into any ETL that needs data cleaning. WAPMixin can be added to any pipeline that writes to Iceberg. They compose without knowing about each other.
The Hook System
Mixins define what behavior a pipeline has. Hooks define when that behavior runs. The hook system is the mechanism that makes composition work at runtime.
Every hook registers at a specific pipeline stage with a priority:
class DeduplicationMixin: @register_hook(ProcessingHook.POST_EXTRACT, priority=10) def deduplicate_data(self, context: ETLContext): df = context.get_dataframe("raw_data") # Window-based deduplication by composite key window = Window.partitionBy( "year", "month", "day", "id", "timestamp" ).orderBy("timestamp") df_deduped = df.withColumn("rn", row_number().over(window)) \ .filter(col("rn") == 1).drop("rn") context.add_dataframe("deduplicated_data", df_deduped)class CleaningMixin: @register_hook(ProcessingHook.POST_EXTRACT, priority=20) def clean_data(self, context: ETLContext): df = context.get_dataframe("deduplicated_data") # Drop columns, trim whitespace, regex replace, filter invalid records # ... context.add_dataframe("cleaned_data", df)class EnrichmentMixin: @register_hook(ProcessingHook.POST_EXTRACT, priority=30) def enrich_data(self, context: ETLContext): df = context.get_dataframe("cleaned_data") # Add derived columns and mappings # ... context.add_dataframe("cleaned_data", df)Priority ordering is the key. DeduplicationMixin runs at priority 10 (dedup first), CleaningMixin at 20 (clean the deduped data), EnrichmentMixin at 30 (enrich after cleaning). The framework reserves priorities 1-9 for internal hooks; user hooks start at 10.
The ETLContext object flows through the pipeline, carrying named DataFrames, metrics, runtime config, and execution metadata between hooks — if you are familiar with Go, think of it as similar to context.Context. Each hook reads from and writes to the context, creating a data flow chain without hooks needing to know about each other. DeduplicationMixin produces deduplicated_data; CleaningMixin consumes it and produces cleaned_data; EnrichmentMixin enriches cleaned_data in place.
Available hook points span the full pipeline lifecycle: PRE_EXTRACT, POST_EXTRACT, PRE_TRANSFORM, POST_TRANSFORM, PRE_COMPACT, POST_COMPACT, PIPELINE_START, PIPELINE_END, PIPELINE_ERROR, and WAP-specific hooks for audit workflows.
Config-Driven Pipelines
The Python class defines what the pipeline does (through mixin composition). The YAML config defines where it reads, where it writes, and how Spark is tuned:
environment: devapp_name: data-cleaning-etl-daily
catalog_config: catalog_name: my_lakehouse catalog_uri: https://catalog.example.com/catalog warehouse: my-warehouse
data_sources: raw_data: extractor: iceberg_table catalog: my_lakehouse namespace: silver table: data_raw prune_date_partitions: true partition_columns: [year, month, day]
targets: cleaned_output: compactor: iceberg_table catalog: my_lakehouse namespace: silver table: data_cleaned schema_class: schemas.DataCleanedTableSchema mode: overwrite_partitions create_if_not_exists: true input: cleaned_data
wap: enabled: true branch_prefix: "wap" on_failure: "rollback"
# Anything you put here is available in ETLContext at runtimeadditional_settings: dedup_key: ["id", "timestamp"] null_fill_defaults: {"score": 0, "label": "unknown"} filter_threshold: 0.95A data engineer adding a new source does not touch Python — they add a data_sources entry. Changing shuffle partitions or S3A settings is a config change, not a code change. The YAML is infrastructure; it changes when you tune Spark or switch environments. The hooks are business logic; they change when the data model evolves. They evolve at different speeds.
The framework handles all the boilerplate: Spark session creation, Iceberg catalog registration, S3A client configuration, shuffle plugin setup. None of that leaks into the ETL code.
Project Organization
Convention matters more than clever structure. When every ETL module looks the same, onboarding is faster, code reviews are easier, and no one has to guess where the config or tests live.
A repo is a logical group of related ETLs — for example, all pipelines in a data domain (raw ingestion, cleaning, deduplication, aggregation) live in one repo. Each ETL module follows the same skeleton:
my-etl/├── raw/│ ├── config/│ │ ├── dev-daily.yaml│ │ └── dev-bulk.yaml│ ├── helpers/│ │ └── type_conversion_hook.py│ ├── schemas/│ │ └── data_raw.py│ ├── tests/│ │ ├── test_raw_etl.py│ │ └── test_raw_schema.py│ ├── raw_daily.py│ └── raw_date_range.py├── cleaned/│ ├── config/│ ├── helpers/│ ├── schemas/│ ├── tests/│ ├── cleaned_daily.py│ └── cleaned_date_range.py├── enriched/│ ├── ...│ └── housekeeping/└── aggregated/ └── ...Every module has the same layout: config/ for environment-specific YAML, helpers/ for hook mixins, schemas/ for Iceberg table definitions, tests/ for unit and integration tests, and the ETL entry points at the module root. Daily and bulk (date range) variants share the same hooks and schemas but use different configs tuned for their workload profile.
Factory-Based Components
Extractors and compactors are created through a factory registry. When the framework reads extractor: iceberg_table or compactor: iceberg_table from config, it looks up the corresponding class in the registry and instantiates it:
class ExtractorFactory: _registry = { S3ParquetExtractorConfig: S3ParquetExtractor, IcebergTableExtractorConfig: IcebergTableExtractor, }
@classmethod def register(cls, config_type, extractor_class): cls._registry[config_type] = extractor_classAdding a new extractor for a different ecosystem — say Kafka, Delta Lake, or a REST API — means writing the extractor class and registering it with the factory. Existing pipelines are untouched. The same pattern applies to compactors: IcebergTableCompactor, S3ParquetCompactor, and ParallelIcebergTableCompactor (for concurrent writes to multiple tables) are all interchangeable through the factory.
Iceberg Table Lifecycle
Iceberg comes with a lot of operational overhead that every pipeline would otherwise handle ad-hoc. The framework absorbs it:
Schema-driven table creation. The schema_class in the target config points to a Python class that defines the table’s schema, partition spec, properties, and DDL statements. No external schema registry needed — the schema lives in the ETL codebase, versioned alongside the pipeline code, and is interpreted at import time. The framework generates the DDL, creates the table if it does not exist, seeds an initial empty snapshot (required for proper WAP branch ancestry), and applies write ordering — all automatically.
class DataCleanedTableSchema(TableSchema): @property def schema(self) -> StructType: return StructType([...])
@property def table_properties(self): return { "write.metadata.delete-after-commit.enabled": "true", "write.metadata.previous-versions-max": "3", }
@property def additional_ddl_statements(self): return [ "ALTER TABLE {table} WRITE LOCALLY ORDERED BY timestamp, id" ]Write-Audit-Publish. The compactor handles WAP automatically when enabled in config — creates a branch, writes data, runs audits (row count, schema validation), and publishes to main only if audits pass. Rollback is automatic on failure.
Housekeeping. Snapshot expiration, orphan file cleanup, data compaction, and manifest compaction are all config-driven. A housekeeping job is the same pattern as an ETL — a class with mixins and a YAML config:
class MyHousekeeping(HousekeepingCLIMixin, StandardHousekeeping): pass # All behavior from configSchema evolution. The compactor supports enable_schema_evolution: true in config, which automatically adds new columns from the DataFrame to the Iceberg table without manual ALTER TABLE statements.
Testing Without a Spark Cluster
Spark tests are slow. Starting a JVM, initializing a SparkSession, running even a trivial transformation — that is 30-60 seconds before a single assertion. In CI, this adds up fast.
We use DuckDB’s experimental PySpark API as a drop-in replacement for unit tests. DuckDB implements enough of the DataFrame API to run transformations, joins, and aggregations without a JVM:
from duckdb.experimental.spark.sql import SparkSession as DuckDBSparkSession
spark = DuckDBSparkSession.builder.appName("test").getOrCreate()# Same DataFrame API, no JVMdf = spark.createDataFrame([("a", 1), ("b", 2)], ["key", "value"])result = df.filter(df.value > 1)The framework provides an ETLTestHarness that runs full pipeline workflows in test mode and returns structured results:
@dataclassclass ETLTestResult: success: bool execution_time: float input_records: int output_records: int validation_errors: List[str] performance_metrics: Dict[str, Any]Unit tests using DuckDB run in seconds. Integration tests using a real SparkSession run against local Iceberg catalogs. The separation keeps CI fast while still validating the full stack before deployment.
What We Learned
Composition over inheritance. Mixins and hooks compose better than deep class hierarchies. A data engineer assembles behavior by listing mixins in the class declaration — no need to understand or override framework internals.
Declarative infrastructure, imperative business logic. Spark tuning, catalog settings, shuffle config — declarative in YAML. Deduplication logic, data cleaning rules, enrichment steps — imperative in hooks. Best of both worlds, and they evolve at different speeds.
Test without the full stack. DuckDB for unit tests, real Spark for integration. The DuckDB path runs in seconds and catches most logic errors. The Spark path runs in CI and catches serialization and catalyst issues.
The framework pays for itself after the third pipeline. The first two pipelines feel like overhead — learning the config format, writing the first hooks. By the third, you are reusing existing mixins and writing only the config. By the tenth, new pipelines take an afternoon instead of a week.