Spark on Spot with S3 Shuffle
How S3 shuffle lets us run Spark executors 100% on spot instances with Karpenter, cutting compute costs 70-85%.
The conventional wisdom is that Spark and spot instances don’t mix. A reclaimed node takes its shuffle data with it, forcing Spark to recompute entire map stages — potentially hours of wasted work. For jobs that shuffle terabytes, that risk makes spot a non-starter.
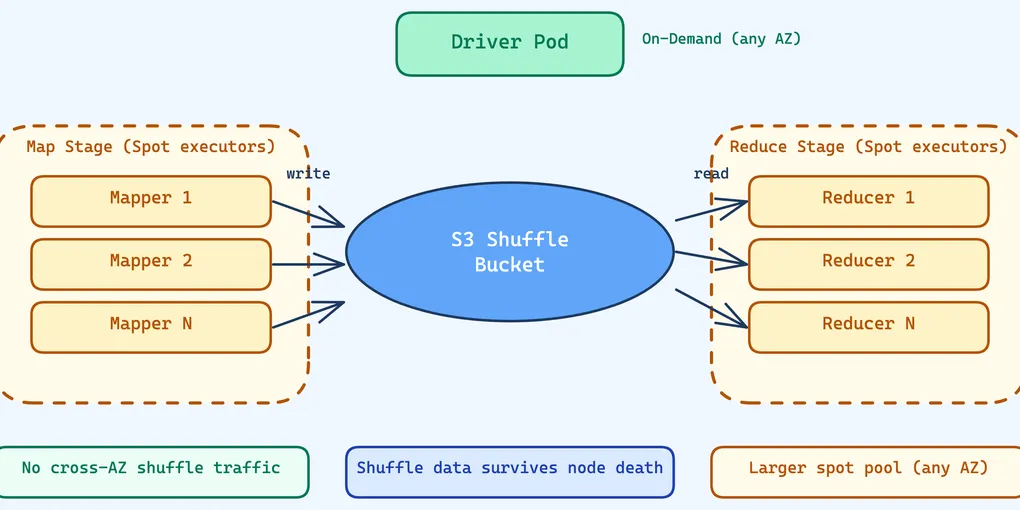
We run Spark executors 100% on spot. The key is externalizing shuffle data to S3 so it survives node death. When a spot instance gets reclaimed, the completed shuffle output is already safe in S3. Spark retries only the tasks that were in-flight on that node — not the entire stage that produced the data.
This post covers the architecture: how the S3 shuffle plugin works, how Karpenter provisions spot nodes, and why removing the AZ constraint gives us access to a much deeper spot capacity pool.
Why Spot Matters
Spark ETLs are compute-heavy, bursty workloads. A daily pipeline might need 50 executors for two hours, then nothing until tomorrow. That’s exactly the workload profile spot instances are designed for.
The savings are significant. For example, a job running 50 r6i.4xlarge executors for two hours costs ~$100 on-demand (r6i.4xlarge is ~$1.008/hr in us-west-2). The same job on spot typically costs $15–30 — spot pricing for that instance runs $0.15–0.30/hr. That is a 70–85% reduction in compute spend for a single run.
But with local-disk shuffle, spot is risky. Spark’s default SortShuffleManager writes shuffle output to the executor’s local disk. If that executor gets reclaimed, the shuffle data is gone. Spark’s only option is to re-run the map tasks that produced it — which means re-reading input data, re-sorting, and re-writing. For a stage with thousands of map tasks, that can mean recomputing hours of work.
We covered the general Spark-on-Kubernetes setup in a previous post. This post focuses on what makes spot viable: S3 shuffle and the Karpenter infrastructure that supports it.
S3 Shuffle — The Architecture
The IBM spark-s3-shuffle plugin replaces Spark’s local-disk shuffle with S3 writes. Instead of writing shuffle data to the executor’s ephemeral disk, mappers write to a shared S3 bucket. Reducers read their partition data from S3 using byte-range requests.
At a high level: each map task writes all its shuffle output into a single S3 object (a .data file) with a companion .index file that records byte offsets for each reduce partition. On the read side, a reducer looks up its partition’s byte range in the index, then issues a range-read GET to S3 for exactly the bytes it needs.
The plugin hooks into Spark through two key mechanisms. First, S3ShuffleWriter.stop() updates the MapStatus location to FALLBACK_BLOCK_MANAGER_ID — this tells Spark’s MapOutputTracker that the shuffle data is not on any executor’s local disk. When a reducer needs data, Spark routes the fetch to S3 instead of trying to contact the (potentially dead) executor.
Second, the plugin’s driver component declares supportsReliableStorage() = true. This tells Spark that shuffle data survives executor failures, enabling aggressive executor decommissioning and dynamic allocation without the risk of losing shuffle output.
Configuration is straightforward:
sparkConf: spark.shuffle.manager: "org.apache.spark.shuffle.sort.S3ShuffleManager" spark.shuffle.sort.io.plugin.class: "org.apache.spark.shuffle.S3ShuffleDataIO" spark.shuffle.s3.rootDir: "s3a://spark-ephemeral-bucket/shuffle/pipeline-name/" spark.shuffle.compress: "true" spark.shuffle.spill.compress: "true" spark.io.compression.codec: "lz4" # Graceful executor shutdown on spot interruption — supportsReliableStorage() # tells the decommissioner shuffle data is already durable in S3, nothing to migrate spark.decommission.enabled: "true"Each ETL pipeline writes to its own prefix under spark.shuffle.s3.rootDir, so shuffle data from different jobs never interferes. LZ4 compression keeps the S3 object sizes manageable without burning CPU on the critical path. We point all shuffle data to a dedicated ephemeral S3 bucket with lifecycle policies to clean up old data.
No Cross-AZ Shuffle Traffic
With traditional local-disk shuffle, executors exchange shuffle data directly over the network — each reducer fetches from every mapper. If executors are spread across availability zones, that shuffle traffic crosses AZ boundaries. AWS charges for cross-AZ data transfer, and for a job shuffling terabytes, those costs add up fast. That’s why our general spark pool pins to a single AZ (us-west-2a).
S3 shuffle changes the equation entirely. The data flow is executor → S3 → executor, not executor → executor. S3 is a regional service — accessing it from us-west-2a costs the same as from us-west-2c. There is no cross-AZ penalty for the shuffle data itself.
The only traffic between driver and executors is control messages: heartbeats, task assignments, status updates. This is kilobytes, not terabytes. The cost of cross-AZ control traffic is negligible.
This is why the shuffle executor pool removes the AZ constraint. We tune the S3A client for maximum throughput:
spark.hadoop.fs.s3a.fast.upload: "true"spark.hadoop.fs.s3a.fast.upload.buffer: "bytebuffer"spark.hadoop.fs.s3a.max.total.tasks: "500"spark.hadoop.fs.s3a.threads.max: "500"spark.hadoop.fs.s3a.connection.maximum: "500"Direct byte buffers (bytebuffer) keep upload data off-heap to avoid GC pressure. 500 concurrent connections and threads give each executor enough parallelism to saturate its network link to S3.
More Room for Spot Capacity
Spot pricing and availability vary by AZ. When you pin executors to a single AZ, you compete for capacity in one spot pool. Remove the constraint and Karpenter can draw from all three AZs — tripling the available spot inventory.
The instance diversification compounds this effect. Our shuffle pool lists 15 instance types: 5 sizes across 3 generations (r5, r6i, r7i). Each instance type in each AZ has its own spot capacity pool. That’s 15 × 3 = 45 independent spot pools that Karpenter can draw from, compared to 4 types × 1 AZ = 4 pools for our general-purpose spark pool.
This combination — no AZ restriction plus multi-generation instance diversity — is only possible because S3 shuffle eliminates the need for co-located shuffle data. With local-disk shuffle, spreading across AZs creates a cross-AZ data transfer problem. With S3 shuffle, it’s purely a benefit.
When spot capacity is scarce for one instance type in one AZ, Karpenter simply picks another. The result is that we almost never see provisioning failures for the shuffle pool, even during peak hours.
What Happens When Spot Reclaims a Node
Here’s the recovery timeline when a spot instance gets reclaimed mid-job:
- Executor running — tasks are processing, writing shuffle output to S3
- Spot reclamation — AWS reclaims the instance. The executor process dies.
- Karpenter provisions replacement — within ~30 seconds, a new node is ready (the 600-second
driverPodCreationGracePeriodgives plenty of buffer) - Spark retries failed tasks — only the tasks that were in-flight on the dead executor need to re-run. Tasks that had already completed are fine — their shuffle output is in S3.
- New tasks read existing data — the retried tasks write their shuffle output to S3. Reducers read from all mappers’ S3 output, including the data written by the original executor before it died.
Contrast this with local-disk shuffle: step 4 would require re-running every map task whose output was on that node, not just the in-flight ones. If 100 tasks had completed on that executor, all 100 would need to recompute. With S3 shuffle, those 100 tasks’ output is already safe in S3.
This is what makes 100% spot viable for executors. The blast radius of a spot reclamation is a handful of in-flight tasks, not an entire map stage.
Cost Attribution
Every Spark driver and executor pod carries Airflow tracking labels:
labels: airflow-dag-id: "{{ dag.dag_id }}" airflow-task-id: "{{ task.task_id }}" airflow-execution-date: "{{ ds }}" etl-module: "{{ dag_run.conf.get('etl_module', 'unknown') }}"These feed into cost monitoring tools, letting us break down compute spend by DAG, task, and ETL module. Combined with Karpenter’s discovery tags on EC2 instances, we get full cost attribution from Kubernetes pod to AWS bill.
What We Learned
S3 shuffle is the architectural prerequisite for spot. Without it, executor loss means re-computing shuffle data — a cost that makes spot too risky for large jobs. With it, shuffle data survives node death, and spot becomes not just viable but the default.
Remove AZ constraints when shuffle goes to S3. Cross-AZ data transfer costs disappear because shuffle data flows through S3 (regional), not between executors. Removing the AZ constraint gives Karpenter access to 3× the spot inventory.
Diversify instance types aggressively. 15 instance types across 3 generations means 45 independent spot pools across 3 AZs. Karpenter almost always finds capacity.
Keep drivers on-demand. Driver death kills the entire job. The cost premium of on-demand for a single small instance per job is trivial compared to the cost of a failed job.
Prefer checkpointing over caching. Cached data is lost when a spot node gets reclaimed. Checkpointing writes to durable storage (S3), so it survives node death — the same principle that makes S3 shuffle work.
S3 shuffle gave us the architecture. But at scale, the S3 request bill and executor hangs told us we were not done yet. In Part 2: Taming S3 Shuffle at Scale, we cover the GET request explosion, prefix throttling, and threading edge cases that emerge when S3 shuffle meets production concurrency.